












CAPTCHA Nedir? Nasıl Gelişti?
Günümüzde her internet kullanıcısı, neredeyse her ziyaret ettiği sitede çeşitli süreçler yaparken, hatta siteye girerken bile muvaffakiyetle …

REKLAM ALANI
Günümüzde her internet kullanıcısı, neredeyse her ziyaret ettiği sitede çeşitli süreçler yaparken, hatta siteye girerken bile muvaffakiyetle tamamlamaları gereken bir teste giriyorlar: CAPTCHA. Carnegie Mellon Bilgisayar Bilimleri Okulu’ndaki grup tarafından geliştirilen bu test, siteyi ziyaret eden kişinin gerçek bir kişi olup olmadığını anlamak için kullanılıyor.
CAPTCHA, bugüne kadar pek çok farklı temayla karşımıza çıktı. Günümüzdeyse bize ya trafik ışıkları seçtiriyor, ya da birkaç fotoğraf ortasından içinde muhakkak bir objenin olduğu fotoğrafları seçmemizi istiyor. Pekala, vakit zaman başarısız olup hudut krizi geçirmemizi sağlayan, “Acaba robot muyum ben?” diye düşünmemize neden olan CAPTCHA, hangi gayeyle ve nasıl geliştirildi ve günümüze kadar nasıl bir gelişimden geçti? Gelin her gün karşılaştığımız bu testi tanıyalım.
- Not: Teknoloji, daima üstüne katarak geliştirildiğinden yazının tamamını okumanızı tavsiye ederim. Aksi halde önemli noktaların irtibatlarını kaçırabilirsiniz.
Öncelikle CAPTCHA nedir?
YAZI ARASI REKLAM ALANI

CAPTCHA, “Completely Automated Public Turing test to tell Computers and Humans Apart (Bilgisayarları ve İnsanları Ayırmak İçin Büsbütün Otomatik Genel Turing testi” sözünün kısaltmasıdır. Bu testte Turing testinin işleyişinde yer alan sorgulayıcı, CAPTCHA’nın algoritmasının ta kendisidir. Sorgulayıcımıza, CAPTCHA’ya verdiğimiz karşılıklarda bizim bir bilgisayar olmadığımızı kanıtlamamız gerekir. Fakat hakikat karşılık verirsek, Turing testini geçmiş ve istediğimiz içeriğe erişmiş oluruz.
CAPTCHA nasıl ortaya çıktı?
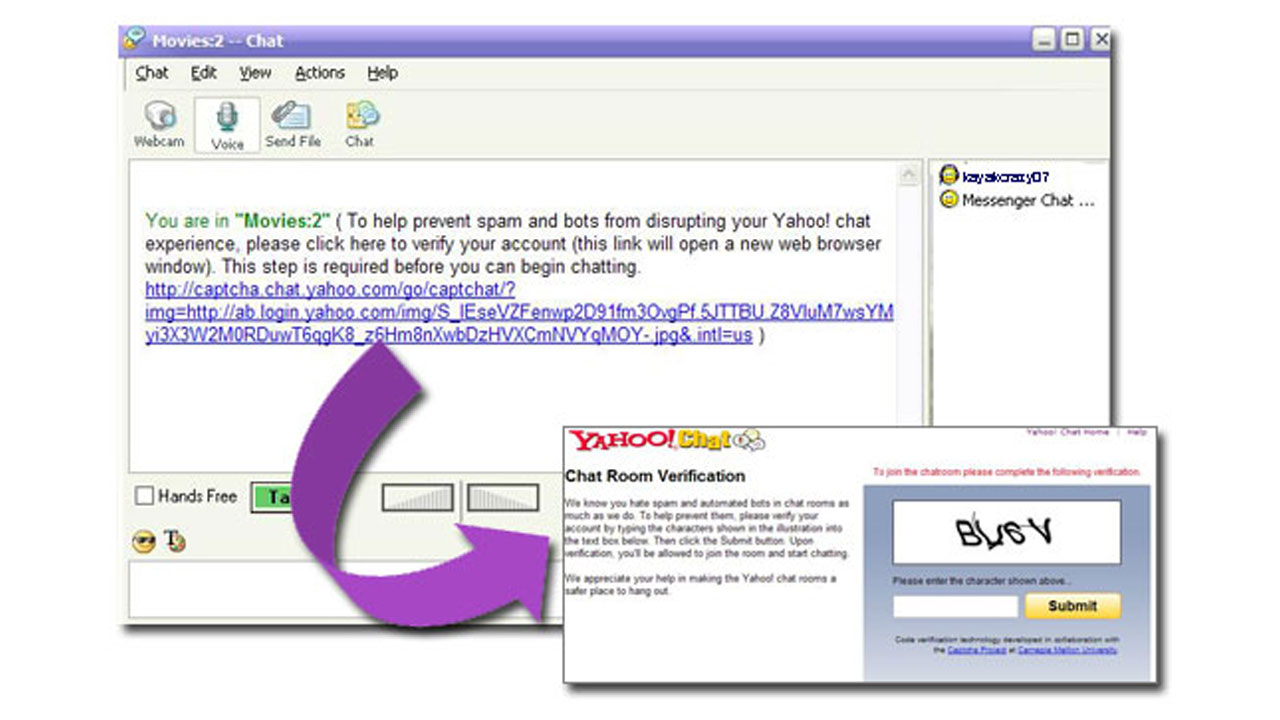
CAPTCHA, Carnegie Mellon Bilgisayar Bilimleri Okulu’nda Luis von Ahn tarafından yönetilen, beraberindeki Manuel Blum, Nicholas J. Hopper ve John Langford tarafından geliştirildi. Sistemi geliştirme fikriyse dev bir şirket sayesinde ortaya çıktı. Luis von Ahn, sistemin geliştirilme kıssasını kendi ağzıyla anlattı.
2000 yılında, şimdi doktorasının birinci yılında olan Luis, o vaktin en dev şirketlerinden Yahoo’nun başmühendisinin verdiği konuşmaya katıldı. Konuşmanın konusu, Yahoo’nun bir türlü çözemediği 10 problemdi. İşte bu sorunlardan birisi de Luis ve takımının bugün terler dökmemizi sağlayan, yıllar içinde yapay zekâ tartışmaları açan CAPTCHA fikrini ateşledi.
Yahoo, o devirde milyonlarca e-posta adresi açmak için program yazan kullanıcılarıyla baş etmeye çalışıyordu ve bunun önüne bir türlü geçemiyordu. Yazılan programlar, Yahoo’da sırf formu doldurarak e-posta adresi oluşturuyor ve bunu hiç durmadan yapabiliyordu. Koskoca Yahoo, bunun önüne bir türlü geçemedi.
Luis von Ahn ve takımı de bunun için ziyadesiyle mantıklı bir tahlille geldi: Bilgisayarları ve insanları birbirinden ayırt edebilecek bir test. Bu test, her yaştan ve dünyanın her yerinden, kısaca herhangi bir insan tarafından çözülmek zorundaydı, ama bilgisayarlar bu testi geçmemeliydi. İşin güç kısmı da aslında buydu. Ancak takım, bunun için insan tabiatına başvurdu: Biz, karakterleri ve metinleri kolay bir biçimde hangi biçimde ve ortamda olurlarsa olsun, lisanı fark etmeksizin tanıyabiliyorduk. Fakat bilgisayarlar, bu karakterleri sırf kendilerine gösterilen biçimde tanıyabiliyorlardı. Olağan bu, o vaktin bilgisayarları için geçerliydi. Bu hususa da birazdan değineceğiz.
İlk CAPTCHA sistemi de böylece ortaya çıktı:

CAPTCHA’da kullanıcıya gösterilen testlerini birinci sürümü, değişmeyen iki sözcükten oluşan ve şekli bozulmuş bir formda gösterilen bir diziydi. Bilgisayara bu sorunun yanıtı gerçek bir formda veriliyor ve kullanıcıdan o yanıt isteniyordu. Beşerler, hali bozulmuş karakterleri tanıyabilirken bilgisayarlar bu karakterleri tanıyamadığından otomatik olarak algılayamıyorlar, münasebetiyle testi tamamlayamıyorlardı.
Yahoo, CAPTCHA’nın bu birinci sürümünü sorun yaşadığı e-posta oluşturma sayfasında kullanmaya başladı. CAPTCHA’nın eklendiği birinci haftalarda sistem, milyonlarca sefer kullanıldı ve hakikaten de insanları bilgisayarlardan ayırmada başarılı oldu. Ancak bu sistemle birlikte aslında büyük de bir sorun oluşmaya başladı: Yapay zekâ, verilen karşılıklarla gelişiyor, hatta CAPTCHA karşılıkları kara borsaya düşüyordu.
CAPTCHA, bilgisayar ve insanı ayırırken bilgisayarı akıllandırdı:
Kullanıcıların CAPTCHA’ya verdikleri yanıtlarla birlikte bu yanıtlar aslında bir yere kaydoluyordu. Böylece bir bilgisayar, yanıtı bilinen bir CAPTCHA’yla karşılaştığında o karşılığı yapıştırarak testten muvaffakiyetle geçiyor, bilgisayar tarafından ‘insan’ olarak tanımlanıyordu. Hatta bu durum o kadar önemli bir hale geldi ki ‘CAPTCHA çiftlikleri’ kuruldu ve parayla çalışan insanlar, binlerce CAPTCHA çözerek bu testlerin doğru karşılıklarını botlar için kaydetti. Böylelikle CAPTCHA, ikinci sürüme geçmeye zorlandı.
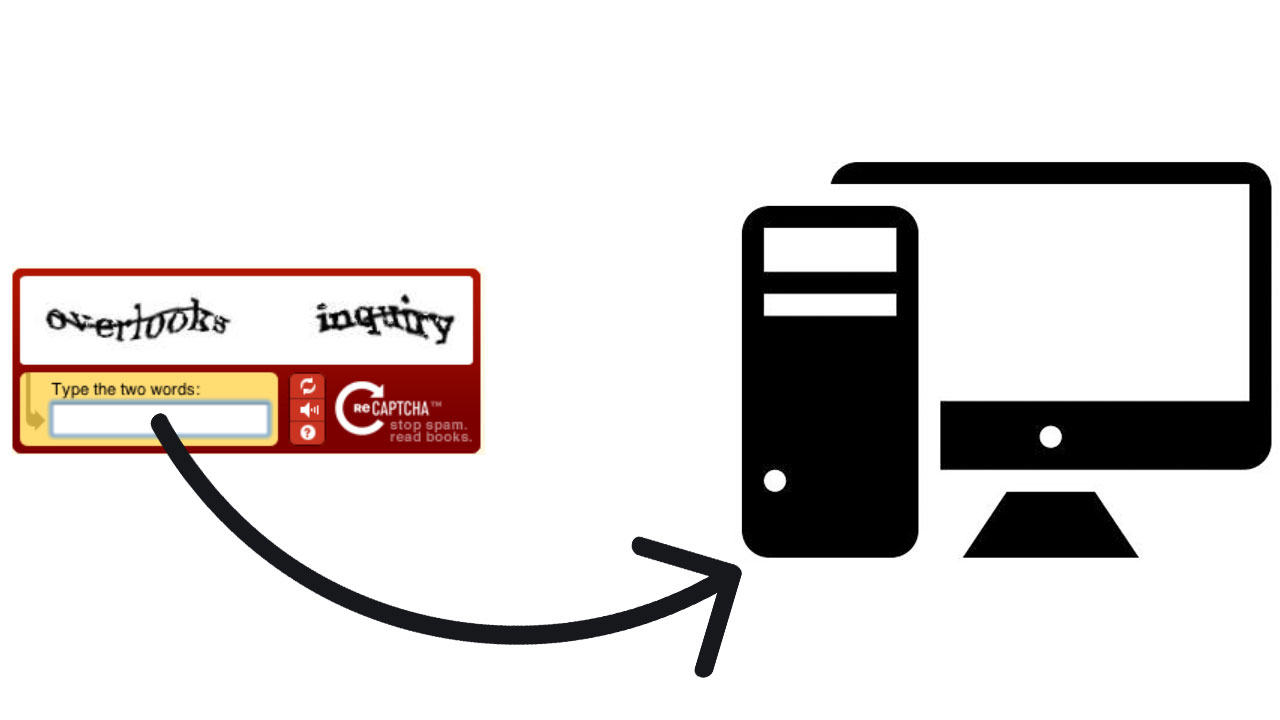
İkinci sürüm CAPTCHA: reCAPTCHA:

CAPTCHA’nın bir sonraki gelişimi 2005’te gerçekleşti. Bu sefer CAPTCHA, ‘reCAPTCHA’ olarak isimlendirildi. Bu sürümde artık iki sözcük değişmez değil, bunlardan birisi değiştirilebilir hale getirildi. Sözcüklerden birisi bilgisayarın yanıtını bildiği bir sözcük, başkasıysa kitaplardan, makalelerden yahut rastgele bir içerikten alınan ve karakterleri düzgün olmayan rastgele bir sözcüktü. Bilgisayar, bu sözcüğün karşılığını bilmiyordu. Pekala, bilgisayar, bu ikinci sözcüğün yanıtının gerçek olup olmadığını nasıl anlıyordu?
reCAPTCHA, birisi bilgisayar tarafından bilinen ve başkası bilinmeyen tıpkı iki sözcüğü tek bir kullanıcıya değil, birden fazla kullanıcıya gösteriyordu. Böylelikle birden fazla kullanıcı, tıpkı soruya aynı yanıtı verdiğinden yanıt yanlışsız olarak algılanıyordu. Bu süreç boyunca bozuk yazıma yer veren binlerce makale ve kitap elle taranıyor, ikinci sözcük oluşturuluyordu.
Google’ın reCAPTCHA’yı satın alması sistemi daha da akıllandırdı:
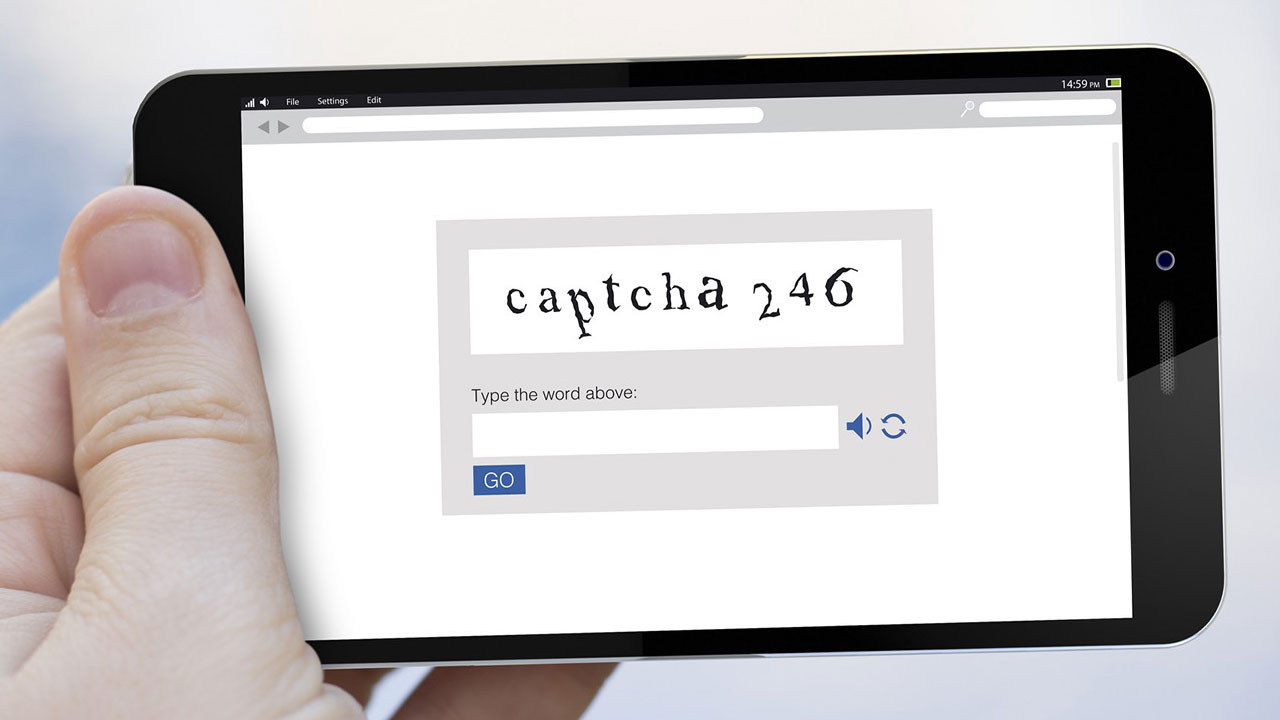
2009 yılına gelindiğinde Google, reCAPTCHA’yı satın aldı. Şirketin gerçekleştirdiği birinci işlerden birisi ikinci sözcüğün oluşturulması için gereken taramayı otomatikleştirmekti. Gördüğümüz o eski kitaptan alınmış üzere gözüken gri art planlı sözcükler, hakikaten de eski kitaplardan alınmıştı. Şirketin bu prosedürüyle metinleri tarayan bilgisayar, sözcüklerin bozuk hallerini tanıyabilir hale geldi. Artık bozuk yazılmış bir sözcük gösterildiğinde bilgisayarlar bunu tanımakta zahmet çekmiyordu. Bilgisayarlar, bozuk metinleri okumayı öğrenmiş oldu.
2014 yılında Google’ın makine tahsili alanında gerçekleştirdiği bir test, bilgisayarların ne derece akıllandığını da dehşetli bir formda ortaya koydu. Bu testin sonuçlarına nazaran beşerler, bozuk yazılmış sözcükleri %33 oranında hakikat okuyabiliyordu. Bir vakitler genişletilmiş karakterleri bile algılayamayan yapay zekâysa bu testten %99,8 oranında doğruluk sonucu aldı. Böylece CAPTCHA metodunda de devrimsel bir değişikliğe gidildi.
İkinci sürümün ikinci sürümü: reCAPTCHA V2 ve No CAPTCHA reCAPTCHA
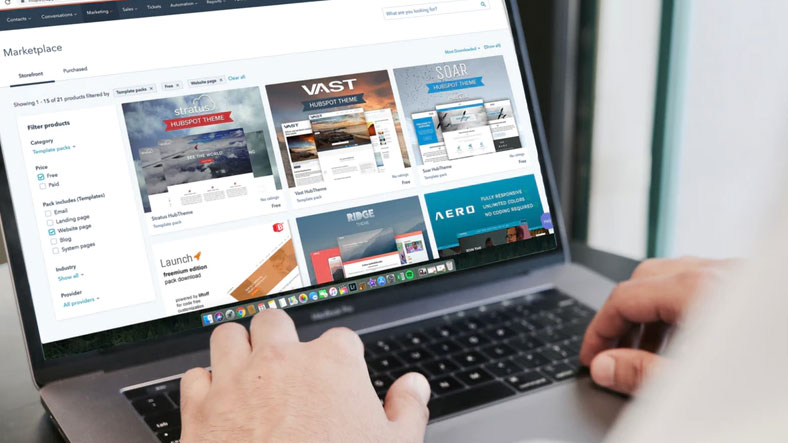
Aynı yıl testin akabinde reCAPTCHA V2 sürümüne geçiş yapıldı. Bu sürümde artık kullanıcılar metinlerle karşılaşmıyor, günümüzdeki üzere resimlerle karşılaşıyordu. Kullanıcılara belirtilen bir objenin bulunduğu görselleri seçmeleri söyleniyordu. Bununla birlikte Google, “No CAPTCHA reCAPTCHA (CAPTCHA Olmayan reCAPTCHA)” ismini verdiği bir sistemi de bununla birlikte yürürlüğe soktu.
O periyotta sistemi kullanan birinci isimler Snapchat, WordPress ve HumbleBundle’dı. Yeni sistemle birlikte kullanıcılar, sitelerde “I’m not a robot (Ben robot değilim)” denetim kutusunu görmeye başladı. Sistemin çalışma biçimiyse aslında esasen teste gelmeden evvel kullanıcıları bilgisayarlardan büyük oranda ayırmayı başarıyordu.
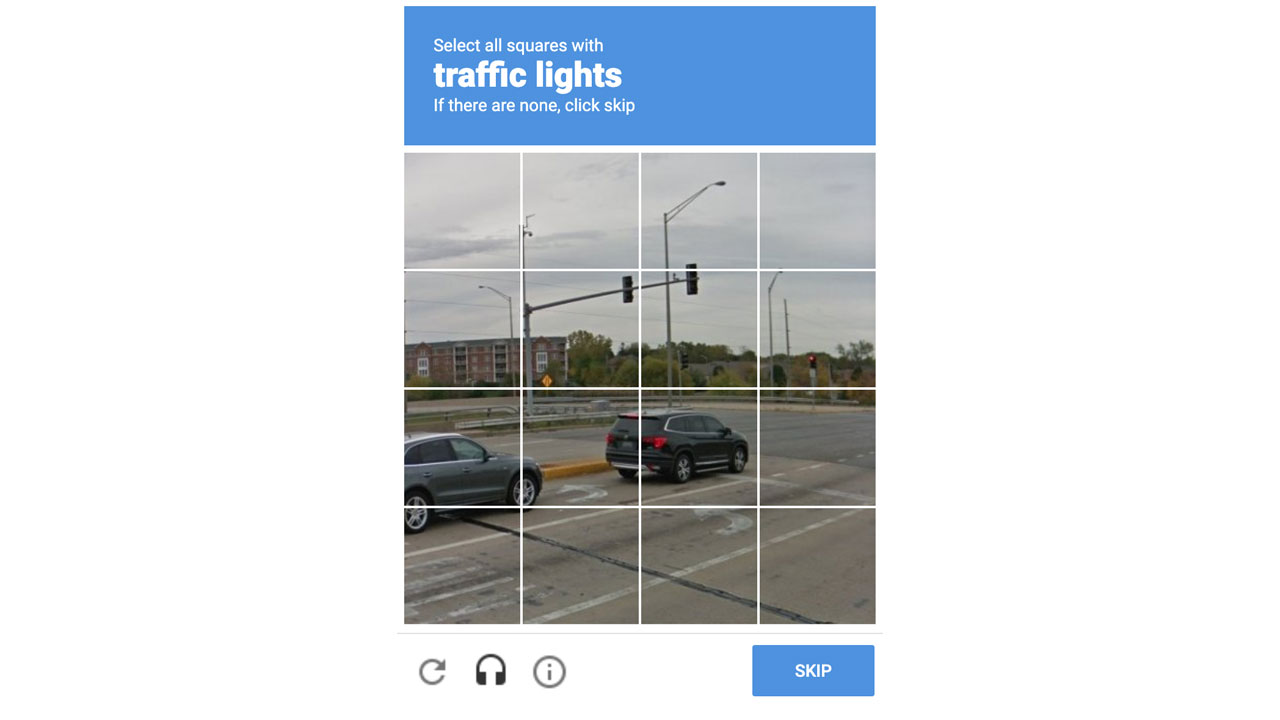
“Gelişmiş Risk Analizi” isimli daima geride çalışan bir sistem, kullanıcıların siteyle etkileşimini izliyordu. Evet, internette daima izleniyoruz. Hatta sayfada nasıl gezindiğimiz bile kaydoluyor, teknolojileri geliştiriyor. Kullanıcının davranışları, gerçek beşerden beklenen davranışlarla uyuşuyorsa, I’m not a robot seçeneğine bastığınızda karşınıza hiçbir test çıkmıyor, insan olduğunuz doğrulanıyordu. Ama etkileşim bir insanın etkileşimiyle uyuşmuyorsa, yani bilgisayar, siteye bir bilgisayarın girdiğini düşünüyorsa onlara CAPTCHA’yı gösteriyordu. Bu CAPTCHA da reCAPTCHA V2’yle gelen fotoğraflı CAPTCHA’lardı.
reCAPTCHA V2’nin fotoğraflı doğrulamasıysa elbette yeniden yapay zekâyı geliştiriyordu. Ama bu kere verdiğiniz karşılıklar yüklü olarak korsanlar tarafından değil, Google tarafından kullanılıyordu. Google, günümüzde bile bir manzara içindeki objeleri ayırt edebilmek için bizim CAPTCHA’lara verdiğimiz karşılıkları kullanıyor. Böylelikle, örneğin, kendi kendine giden bir otomobil bir ağacı, bir yangın musluğunu, bir trafik ışığını yahut bir yaya geçidini algılayabiliyor. Anlayacağınız, interneti inançla kullanmamızı sağlayan bu sistem, Google’ın daha da gelişmesini sağlıyor. Kazan – kazan durumu.
Günümüz reCAPTCHA’sı: reCAPTCHA V3

Google, reCAPTCHA’nın yazılar gösteren birinci sürümünü 4 Nisan 2018 tarihinde büsbütün kullanımdan kaldırdı. Günümüzde birçok internet sitesi, halen reCAPTCHA V2’yi kullanmaya devam edebiliyor. Lakin fizikî olarak mevcut olan bu testin yanı sıra bir de 29 Ekim 2018’de piyasaya sürülen reCAPTCHA V3 kullanılıyor. reCAPTCHA V3, reCAPTCHA V2’yi alarak daha da gelişmiş bir hale getirmiş durumda.
2018 yılından bu yana reCAPTCHA V2 yerine V3 kullanan internet siteleri, kullanıcı tarafından rastgele bir etkileşim gerektirmiyor. Bu sitelerde CAPTCHA testi gösterilmiyor. Tersine, internet sitelerinin sahiplerine riskli bir trafikle karşılaşılması durumunda bilgi veriyor. Kullanıcı tecrübesi, CAPTCHA tarafından rastgele bir halde bozulmuyor. Risklerin masrafımı büsbütün internet sitesi sahiplerine bırakılıyor.

Bu çalışma mantığını Google’ın örneğiyle anlatmakta yarar var. Bir alışveriş sitesi sahibisiniz ve son vakitlerde sitenize yüksek ölçüde trafik girdiğini görüyorsunuz. Ancak bu trafik hiçbir halde dönüşümlere çevrilmiyor. Münasebetiyle bunların gerçek müşteri olmadıklarını düşünüyorsunuz. Bu noktada tek bildiğiniz şeyse sitenize yüksek trafik geldiği. Lakin gelen bu trafiğin neyi amaçladığını, sitenizde ne yaptığını bilmiyorsunuz.
İşte reCAPTCHA V3 de tam olarak bunu bilmenizi sağlıyor. Her sayfaya farklı ayrı eklediğiniz reCAPTCHA V3 sistemi, siteye yapılan her girişi takip ediyor. Örneğin eser incelemeleri sayfanıza eklediğiniz sistem, size botların yorum yapmak emeliyle bu sayfaya girdiğini gösteriyor. Yapılan her bir süreç reCAPTCHA tarafından puanlanıyor ve site sahibi, gerçek yorumlarla bot yorumlarını ayırt edebiliyor. Botların ayırt edilmesiyse No CAPTCHA reCAPTCHA’da kullanılan, sitedeki etkileşimin gerçek insan etkileşimiyle karşılaştırılması yöntemiyle yapılıyor.
Tüm bu gelişim, Yahoo’nun yaşadığı meseleye bir tahlil olarak çıkan teknolojinin günümüzde ne kadar büyüyebileceğini ve yapay zekâya nasıl bir katkı yapabileceğini göstermiş oldu. Tıpkı vakitte internetteki parmak izimizin de takip edilebilmesi için yeni teknolojilerin de gelişmesine aracı oldu. reCAPTCHA hakkındaki fikirlerinizi aktardığınız, gelecekte nasıl bir noktaya gelebileceğini anlattığınız yorumlarınızı bekliyoruz.
Kaynaklar: 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
REKLAM ALANI
İLGİNİZİ ÇEKEBİLECEK DİĞER KONULAR



ZİYARETÇİ YORUMLARI
BİR YORUM YAZ